TỔNG QUAN VỀ ĐỀ TÀI
Tổng quan về YOLO
Trong những năm gần đây, phát hiện đối tượng (object detection) đã trở thành một trong những chủ đề nóng trong lĩnh vực deep learning nhờ vào khả năng ứng dụng rộng rãi, dữ liệu dễ dàng chuẩn bị và nhiều kết quả ứng dụng thực tiễn Các thuật toán mới như YOLO và SSD không chỉ có tốc độ xử lý nhanh mà còn đạt độ chính xác cao, cho phép thực hiện các tác vụ gần như theo thời gian thực, thậm chí nhanh hơn cả con người.
Tải xuống TIEU LUAN MOI tại địa chỉ skknchat123@gmail.com với phiên bản mới nhất không bị giảm chất lượng Các mô hình hiện nay ngày càng nhẹ hơn, cho phép hoạt động hiệu quả trên các thiết bị IoT, từ đó tạo ra những thiết bị thông minh.
Thuật toán phát hiện đối tượng (object detection) có thể được ứng dụng đa dạng trong nhiều lĩnh vực, bao gồm việc đếm số lượng vật thể, thanh toán tự động tại quầy hàng, chấm công tự động và phát hiện các vật thể nguy hiểm như súng hay dao Điều này cho thấy rằng object detection có thể được áp dụng rộng rãi trong hầu hết các ngành nghề hiện nay.
Nguồn dữ liệu ảnh phong phú và dễ dàng truy cập qua Google là một lợi thế lớn trong việc huấn luyện mô hình phát hiện đối tượng (object detection).
Có nhiều bạn thắc mắc câu hỏi này YOLO nghe khá giống slogan
“YOLO” trong lĩnh vực phát hiện đối tượng có nghĩa là “You only look once”, cho phép chúng ta phát hiện vật thể chỉ sau một lần quan sát Phương pháp này mang lại tốc độ và hiệu quả cao trong việc nhận diện các đối tượng trong hình ảnh.
YOLO, mặc dù không phải là thuật toán chính xác nhất trong lĩnh vực phát hiện đối tượng, nhưng lại nổi bật với tốc độ nhanh nhất trong các mô hình hiện có Nó có khả năng đạt được tốc độ gần như thời gian thực mà vẫn giữ được độ chính xác tương đối cao so với các mô hình hàng đầu.
YOLO là một thuật toán phát hiện đối tượng, không chỉ dự đoán nhãn cho các vật thể mà còn xác định vị trí của chúng Điều này cho phép YOLO phát hiện nhiều vật thể khác nhau trong cùng một bức ảnh, thay vì chỉ phân loại một nhãn duy nhất.
YOLO có khả năng phát hiện nhiều vật thể trong một bức ảnh nhờ vào các cơ chế thuật toán đặc biệt mà chúng tôi đã nghiên cứu trong đề tài này.
Nguyên lý hoạt động của mạng nơ ron tích chập (Convolutional Neural Network): Đây là mạng nơ ron áp dụng các layer
Convolutional kết hợp với Maxpooling để giúp trích xuất đặc trưng của ảnh tốt hơn Bạn đọc có thể tham khảo Lý thuyết về mạng tích chập neural.
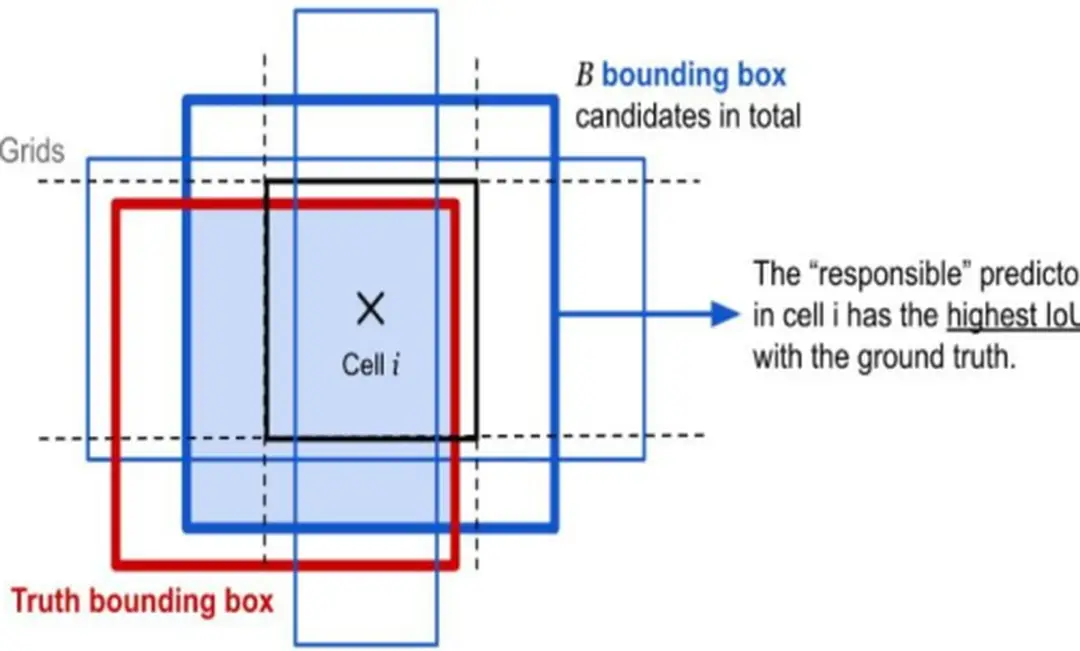
Bounding box là khung hình bao quanh một vật thể trong hình ảnh, giúp xác định vị trí và kích thước của nó Trong khi đó, anchor box là những khung hình có kích thước được xác định trước, được sử dụng để dự đoán bounding box một cách chính xác hơn.
Feature map: Là một khối output mà ta sẽ chia nó thành một lưới ô vuông và áp dụng tìm kiếm và phát hiện vật thể trên từng cell.
Non-max suppression: Phương pháp giúp giảm thiểu nhiều bounding box overlap nhau về 1 bounding box có xác suất lớn nhất.
TIEU LUAN MOI download : skknchat123@gmail.com moi nhat
Thuật toán YOLO
Kiến trúc YOLO bao gồm một mạng cơ sở (base network) với các lớp convolution để trích xuất đặc trưng, kết hợp với các Extra Layers nhằm phát hiện vật thể trên feature map Mạng cơ sở của YOLO chủ yếu sử dụng các lớp convolutional và fully connected, đồng thời có sự đa dạng trong các phiên bản để phù hợp với nhiều hình dạng đầu vào khác nhau.
Hình 1.1: Sơ đồ kiến trúc mạng YOLO
Thành phần Darknet Architecture, được gọi là base network, có chức năng trích xuất đặc trưng Đầu ra của base network là một feature map với kích thước 7x7x1024, được sử dụng làm đầu vào cho các Extra layers nhằm dự đoán nhãn và tọa độ bounding box của vật thể.
In YOLO version 3, the author utilizes a feature extractor network known as Darknet-53, which consists of 53 sequential convolutional layers Each layer is followed by batch normalization and a Leaky ReLU activation function To reduce the output size after each convolutional layer, downsampling is performed using 2x2 filters, effectively minimizing the number of parameters in the model.
TIEU LUAN MOI download : skknchat123@gmail.com moi nhat
Hình 1.2: Các layer trong mạng darknet-53
Các bức ảnh sẽ được điều chỉnh kích thước để phù hợp với hình dạng đầu vào của mô hình Sau đó, chúng sẽ được tập hợp thành một lô (batch) để tiến hành huấn luyện.
TIEU LUAN MOI download : skknchat123@gmail.com moi nhat
YOLO hiện hỗ trợ hai kích thước đầu vào chính là 416x416 và 608x608, mỗi kích thước này có thiết kế các lớp (layers) riêng biệt phù hợp với hình dạng đầu vào Qua các lớp convolutional, kích thước đầu vào giảm dần theo cấp số nhân là 2, cuối cùng tạo ra một feature map với kích thước nhỏ hơn để dự đoán đối tượng trong từng ô của feature map.
Kích thước của feature map sẽ phụ thuộc vào đầu vào Đối với input 416x416 thì feature map có các kích thước là 13x13, 26x26 và 52x52.
Và khi input là 608x608 sẽ tạo ra feature map 19x19, 38x38, 72x72.
- Output của mô hình YOLO là một véc tơ sẽ bao gồm các thành phần: y T =[ p 0 , t x , t y , t w , t h , p 1 , p 2 , p 3 … p c ] boundingbox scoresof c classes
Xác suất dự báo vật thể xuất hiện trong bounding box được ký hiệu là p0 Các tham số tx, ty, tw, và th được sử dụng để xác định bounding box, trong đó tx và ty là tọa độ tâm, còn tw và th là kích thước chiều rộng và chiều dài của bounding box Ngoài ra, p1, p2, p3,…, pc là các véc tơ phân phối xác suất dự báo cho các lớp khác nhau, với scores của c lớp được tính toán dựa trên các yếu tố này.
Hiểu rõ output là yếu tố quan trọng để cấu hình chính xác các tham số khi huấn luyện model qua các open source như darknet Output được xác định theo số lượng classes theo công thức (n_class+5) Nếu bạn huấn luyện 80 classes, output sẽ là 85 Trong trường hợp áp dụng 3 anchors/cell, số lượng tham số output sẽ được tính toán tương ứng.
TIEU LUAN MOI download : skknchat123@gmail.com moi nhat
Hình 1.3: Kiến trúc một output của model YOLO
Hình ảnh gốc được biểu diễn qua feature map kích thước 13x13, nơi mỗi cell chứa 3 anchor boxes với kích thước khác nhau, bao gồm Box 1, Box 2 và Box 3, với tâm của các anchor boxes trùng khớp với cell Đầu ra của YOLO là một véc tơ kết hợp chứa thông tin của 3 bounding boxes, trong đó các thuộc tính của mỗi bounding box được mô tả chi tiết ở dòng cuối cùng của hình ảnh.
1.3.3 Dự báo trên nhiều feature map
YOLOv3 sử dụng nhiều feature map để dự báo, tương tự như SSD Các feature map ban đầu có kích thước nhỏ, giúp phát hiện các đối tượng lớn, trong khi các feature map sau có kích thước lớn hơn, cho phép dự đoán các vật thể nhỏ nhờ vào việc giữ cố định kích thước của anchor box.
TIEU LUAN MOI download : skknchat123@gmail.com moi nhat
Hình 1.4: Các feature maps của mạng YOLOv3
Với input shape là 416x416, output là 3 feature maps có kích thước lần lượt là 13x13, 26x26 và 52x52.
Trong mô hình YOLO, mỗi cell của các feature map sẽ sử dụng 3 anchor box để dự đoán vật thể, dẫn đến tổng số 9 anchor box cho mô hình (3 feature map x 3 anchor box) Trên một feature map hình vuông kích thước S x S, YOLOv3 tạo ra S x S x 3 anchor box, do đó tổng số anchor box trên một bức ảnh sẽ được tính bằng công thức này.
Số lượng 10647 anchor boxes, được tính từ công thức (13 x 13 + 26 x 26 + 52 x 52) x 3, là rất lớn và gây khó khăn cho quá trình huấn luyện mô hình YOLO Việc dự đoán đồng thời cả nhãn và bounding box trên 10647 bounding boxes là nguyên nhân chính khiến cho tốc độ huấn luyện trở nên chậm chạp.
Một số lưu ý khi huấn luyện YOLO:
Khi huấn luyện YOLO sẽ cần phải có RAM dung lượng lớn hơn để save được 10647 bounding boxes như trong kiến trúc này.
Trong các mô hình phân loại, việc thiết lập kích thước batch_size quá lớn có thể dẫn đến tình trạng hết bộ nhớ Để khắc phục vấn đề này, gói darknet của YOLO đã chia nhỏ một batch thành các phân đoạn (subdivisions) nhằm tối ưu hóa việc sử dụng RAM.
Thời gian xử lý mỗi bước trên YOLO chậm hơn nhiều so với các mô hình phân loại Do đó, nên giới hạn số bước huấn luyện cho YOLO ở mức thấp Đối với các tác vụ nhận diện có dưới 5 lớp, dưới 5000 bước là đủ để đạt được kết quả tạm chấp nhận Đối với các mô hình có nhiều lớp hơn, có thể tăng số bước theo cấp số nhân tùy ý.
Để xác định bounding box cho vật thể, YOLO sử dụng các anchor box làm cơ sở ước lượng Những anchor box này được xác định trước và đóng vai trò quan trọng trong quá trình phát hiện đối tượng.
Tải xuống TIEU LUAN MOI tại địa chỉ skknchat123@gmail.com để có thông tin mới nhất về việc xác định vật thể một cách chính xác Thuật toán regression bounding box sẽ điều chỉnh anchor box nhằm tạo ra bounding box dự đoán cho vật thể trong mô hình YOLO.
KHỞI TẠO GOOGLE COLAB
Cấp phép cho Google Colab
4.1 Huấn luyện Yolov3 (trên hệ điều hành Ubuntu) 4.1.1 Chuẩn bị dữ liệu
4.1.1.1 Tải source Darknet về máy: Đầu tiên các bạn tạo thư mục AI_Yolo trên máy tính tại đâu nào tùy bạn nhé Chúng ta sẽ chuyển vào và làm việc trong thư mục này.
Trên Terminal hãy chuyển vào thư mục AI_Yolo bằnh lệnh cd AI_Yolo, sau đó gõ lệnh: git clone https://github.com/pjreddie/darknet
Sau khi chờ vài phút, thư mục AI_Yolo sẽ xuất hiện thêm thư mục darknet cùng nhiều folder bên trong, cho thấy quá trình tải đã thành công Tiếp theo, chúng ta sẽ tiến hành bước biên dịch (make) bằng cách mở file.
Makefile trong thư mục darknet và lưu ý 2 dòng sau:
# dòng GPU bên dưới để là 1 nếu máy bạn có GPU, ngược lại để 0 GPU=0
# dòng OPENCV để 1 nếu bạn muốn dùng thư viện OpenCV OPENCV=0
Mình thường để OpenCV=1 để hỗ trợ mở nhiều định dạng file ảnh hơn Nếu gặp lỗi, các bạn có thể đặt OPENCV=0 cũng không sao, vì hiếm khi mở các file ảnh không phổ biến.
SUDO APT-GET INSTALL LIBOPENCV-DEV
Xong, bây giờ bạn lưu lại file Makefile
4.1.1.2 Chuẩn bị dữ liệu train
Để tạo ra một mô hình chất lượng, bạn cần thu thập dữ liệu huấn luyện từ internet hoặc bất kỳ nguồn nào có sẵn Số lượng dữ liệu càng nhiều, càng tốt; lý tưởng nhất là nên có hàng nghìn ảnh để đảm bảo mô hình hoạt động hiệu quả hơn.
Sau khi có dữ liệu, bạn hãy vào thư mục darknet/data và tạo folder images.
Copy tât cả các ảnh bạn dùng để train vào thư mục images.
TIEU LUAN MOI download : skknchat123@gmail.com moi nhat
HUẤN LUYỆN YOLO TRÊN GOOGLE COLAB
Khởi tạo project darknet
Darknet là một framework mã nguồn mở chuyên về phát hiện đối tượng, được phát triển bằng ngôn ngữ C và CUDA Các mô hình huấn luyện trên Darknet có tốc độ nhanh và dễ dàng cài đặt, hỗ trợ cả CPU và GPU Cộng đồng người dùng Darknet đông đảo và có đội ngũ hỗ trợ nhiệt tình, chính vì vậy nhóm chúng tôi đã chọn Darknet cho dự án của mình.
Tại bước này chúng ta cần clone project darknetGoogleColab mà tôi đã customize lại một chút cho phù hợp với google colab.
Các bạn thực hiện tuần tự như sau:
Step 1: Thay đổi đường dẫn tới folder mặc định là My Drive.
Step 2: Sử dụng command line để clone git project darknetTurtorial từ github repo của bản thân.
Sau khi chạy thành công bạn kiểm tra trên My Drive của Google drive bạn sẽ thấy folder darknetGoogleColab vừa mới được clone về.
Sau đó chúng ta cd vào folder và phân quyền execute module darknet để có thể chạy được các lệnh trên darknet.
TIEU LUAN MOI download : skknchat123@gmail.com moi nhat
Lúc này chúng ta đã có thể sử dụng được các lệnh của dự báo, huấn luyện của darknet trên hệ điều hành ubuntu.
Chuẩn bị dữ liệu
Hiện nay, có nhiều công cụ mã nguồn mở để gán nhãn cho mô hình YOLO, trong đó nhóm em chọn sử dụng labelImg từ pypi vì những lý do cụ thể.
Giao diện UI/UX khá tốt với đầy đủ chức năng: open, load, save,…
Hỗ trợ gán nhãn trên cả 2 định dạng COCO xml format và YOLO default txt format.
Chức năng default bounding box cho phép tự động gán nhãn cho các bức ảnh trong cùng một folder Ví dụ, khi tôi gán nhãn cho sản phẩm cafe, tất cả bức ảnh liên quan đến cafe sẽ được tổ chức trong một folder duy nhất Nhờ đó, tôi không cần phải nhập lại nhãn cho từng bức ảnh mà chỉ cần tạo một default bounding box cho toàn bộ ảnh.
Và rất nhiều các chức năng khác.
Việc cài đặt và hướng dẫn sử dụng các bạn đọc tại labelImg.
Khi huấn luyện mô hình YOLO trên darknet, đầu vào cần thiết là các bức ảnh có định dạng như png, jpg hoặc jpeg.
TIEU LUAN MOI download : skknchat123@gmail.com moi nhat annotation của chúng (định dạng txt) Bên dưới là nội dung của một file annotation.txt.
Nội dung của file annotation sẽ bao gồm:
Các giá trị , , , và đại diện cho tâm và kích thước của bounding box đã được chuẩn hóa, được tính bằng cách chia cho chiều rộng và chiều cao của ảnh, vì vậy các giá trị này luôn nằm trong khoảng [0, 1] Thêm vào đó, là chỉ số đánh dấu các lớp (classes).
Trong trường hợp một ảnh có nhiều bounding box thì file annotation sẽ gồm nhiều dòng, mỗi một bounding box là một dòng.
Cảc ảnh và annotation phải được để chung trong cùng 1 folder Bạn đọc có thể tham khảo qua dữ liệu mẫu Dữ liệu ảnh sản phẩm TMDT.
Lệnh trên sẽ clone dữ liệu về folder traindata trong project của chúng ta.
Khi tạo folder traindata, cần tránh việc đặt tên trùng với folder data mặc định của darknet Nếu tên folder trùng lặp, sẽ dẫn đến lỗi "Cannot load image" khi thực hiện dự báo, và nhãn dự báo của hình ảnh sẽ không hiển thị.
Dữ liệu trong folder img sẽ bao gồm các file ảnh và file annotation (có đuôi txt) của chúng.
4.2.3 Phân chia dữ liệu train/validation
Tải xuống TIEU LUAN MOI tại địa chỉ skknchat123@gmail.com Trong bước này, chúng ta sẽ tạo hai file train.txt và valid.txt, chứa đường dẫn đến các file hình ảnh trong tập train và validation Sử dụng đoạn mã dưới đây, chúng ta sẽ ngẫu nhiên chọn 20 file làm dữ liệu validation, trong khi các file còn lại sẽ được sử dụng làm dữ liệu train.
Cấu hình darknet
4.3.1 Tạo file object name Đây là files chứa tên các classes mà chúng ta sẽ huấn luyện mô hình Trên file này, thứ tự các classes name cần phải đặt đúng với index của nó trong các file label của vật thể. Đoạn code trên sử dụng lệnh echo của bash để tạo và write nội dung vào file obj.names Sau đó, một file obj.names được tạo thành trong project foler Bạn có thể mở file này ra để kiểm tra nội dung.
File config data sẽ khai báo một số thông tin như:
Số lượng classes Đường dẫn tới các file train.txt, test.txt Đường dẫn tới file obj.names
TIEU LUAN MOI download : skknchat123@gmail.com moi nhat
Thư mục backup mô hình huấn luyện.
Chạy lệnh bên dưới để tạo file này.
4.3.3 Tạo file config model Đây là bước quan trọng nhất khi huấn luyện model YOLO Chúng ta sẽ sử dụng file yolov3.cfg để cấu hình mô hình huấn luyện Các bạn download file trên về máy và điều chỉnh các dòng:
Tại các dòng 610, 696, 783: Thay classes thành classes=5 là số lượng classes chúng ta huấn luyện.
In lines 603, 689, and 776, the number of filters is changed to filter0, representing the final layer of the base network Consequently, the output shape varies based on the number of classes, following the formula from the previous article: (n_classes + 5)x3 = (5+5)x3 = 30 The max_batches parameter in line 20 indicates the maximum number of steps for training YOLO models For a dataset with 5 classes, adjusting max_batches to 1000 can yield satisfactory results Additionally, the burn_in value in line 19 specifies the initial number of steps during which the learning rate remains very low, gradually increasing from 0 to the designated learning rate.
Sau khi thiết lập learning_rate ổn định, việc sử dụng giá trị nhỏ cho learning_rate ở những bước đầu sẽ giúp thuật toán hội tụ nhanh hơn Với số lượng max_batches chỉ 5000, cần điều chỉnh burn_in xuống còn 100 Đặc biệt, tại dòng 22, điều chỉnh steps về 00,4500 để bắt đầu giảm dần learning_rate, vì thuật toán đã đạt đến điểm hội tụ và không cần thiết phải giữ learning_rate quá cao.
Sau khi thực hiện các thay đổi xong, các bạn save file lại và push lên project darknetGoogleColab của google driver.
Trước đó, hãy đổi tên lại thành yolov3-5c-5000-maxsteps.cfg để đánh dấu đây là cấu hình cho yolo version 3 với 5 classes và 5000 bước huấn luyện.
Các file config này đã có sẵn trong github repo nên có thể download về sử dụng ngay.
TIEU LUAN MOI download : skknchat123@gmail.com moi nhat
Các hàm phụ trợ
Để thuận tiện cho việc đọc, ghi và hiển thị hình ảnh, tôi sẽ xây dựng các hàm phụ trợ với các chức năng như sau: imShow() dùng để hiển thị hình ảnh từ một đường dẫn, upload() cho phép tải lên một tệp từ máy tính lên Google Drive, và download() giúp tải về một tệp từ một đường dẫn trên mạng.
Huấn luyện mô hình
YOLO được đào tạo trên nhiều mô hình pretrain, sử dụng các bộ dữ liệu ảnh lớn như COCO, Pascal VOC, Imagenet và CIFAR Những bộ dữ liệu này có định dạng và chuẩn mực cao, được đảm bảo bởi các tổ chức và viện nghiên cứu uy tín trên thế giới, do đó, chất lượng dữ liệu hoàn toàn đáng tin cậy.
List các danh sách model pretrain các bạn có thể theo dõi tại Darknet YOLO
In this practical example, we will utilize the pre-trained model darknet53.conv.74, which has been trained on the ImageNet dataset First, we need to clone the weight file to Google Drive For further assistance, please contact us at skknchat123@gmail.com.
TIEU LUAN MOI download : skknchat123@gmail.com moi nhat
Tạo một folder backup để lưu kết quả huấn luyện sau mỗi 1000 steps.
Folder backup này phải trùng với tên với link folder backup đã được khai báo ở step 4.3.3 tạo file config data.
Để giảm thiểu thời gian chờ đợi trong quá trình sao lưu mô hình, tôi đã thiết lập hệ thống tự động sao lưu mô hình sau mỗi 100 bước thay vì 1000 bước Điều này giúp ngăn ngừa các lỗi có thể xảy ra trong 1000 bước đầu tiên khi huấn luyện, đảm bảo rằng dự án của tôi luôn được bảo vệ và cập nhật kịp thời.
4.5.3 Huấn luyện model Để huấn luyện model ta chỉ cần thực hiện lệnh detector train.
!./darknet detector train [data config file] [model config file] [pretrain- model weights] -dont_show > [file log saved]
The [data config file] and [model config file] are essential configuration files, while the [pretrain-model weights] refers to the pretrained model file Additionally, the [file log saved] captures the logging of the training process.
Khi lưu log vào [file log saved], mô hình của bạn sẽ không hiển thị log trên màn hình Nhiều người có thể hiểu nhầm rằng mô hình đã ngừng chạy Để tiếp tục hiển thị log trong quá trình huấn luyện, bạn cần bỏ phần > [file log saved] ở cuối câu lệnh.
Nếu bạn nào gặp lỗi:
CUDA Error: out of memory: File exists
TIEU LUAN MOI download : skknchat123@gmail.com moi nhat
Hãy quay trở lại file yolov3-5c-5000-max-steps.cfg và điều chỉnh tăng subdivisions2 Sau đó train lại model từ đầu.
Quá trình đào tạo mất khoảng 5 giờ, vì vậy hãy kiên nhẫn chờ đợi nếu bạn muốn thấy kết quả Tuy nhiên, nếu bạn muốn có ngay thành phẩm, hãy tải xuống file pretrain nhận diện sản phẩm TMDT của tôi.
Log của chương trình không hiển thị trên màn hình vì đã được lưu vào file yolov3-5c.log Mục đích chính là để lưu trữ log nhằm trực quan hóa hàm mất mát (xem mục 4.5.4) Nếu bạn muốn theo dõi trực tiếp trên màn hình Google Colab, hãy chạy lệnh sau.
!./darknet detector train obj.data yolov3-5c-5000-max-steps.cfg darknet53.conv.74 -dont_show
You can open another Google Colab session to perform section 4.5.4, which focuses on visualizing the loss function Remember to regularly check your internet connection, as Google Colab will automatically terminate offline sessions after one hour This means that if you close Colab or lose internet connectivity, your training process will continue for one hour but will be terminated afterward.
Google Colab cho phép thời gian tối đa cho một phiên làm việc lên đến 12 giờ Tuy nhiên, đối với các bộ dữ liệu lớn, việc huấn luyện mô hình phát hiện đối tượng trên Google Colab trở nên khó khăn và có thể không khả thi.
Kết quả huấn luyện của mô hình ở mỗi bước sẽ được ghi lại trong file yolov3-5c.log, cho phép chúng ta sử dụng file này để trực quan hóa hàm loss function.
Trong dự án git được tùy chỉnh từ darknet, tôi đã phát triển một file để trực quan hóa hàm mất mát (loss function) Ý tưởng thực hiện không phức tạp; chúng ta chỉ cần tìm kiếm trong log các dòng có chứa Average Loss, sau đó trích xuất giá trị của hàm mất mát và tiến hành trực quan hóa Bạn đọc có thể mở file để nghiên cứu chi tiết.
TIEU LUAN MOI download : skknchat123@gmail.com moi nhat
Như vậy đồ thị loss function cho thấy thuật toán đã hội tụ sau khoảng 7000 batches đầu tiên Loss function ở giai đoạn sau có xu hướng tiệm cận gần 1.
Dự báo và ước tính thời gian huấn luyện
Sau khi huấn luyện xong mô hình, kết quả sau cùng sẽ được lưu trong folder backup Để dự báo cho một bức ảnh ta sử dụng cú pháp:
!./darknet detector test [data config file] [model config file] [last-model weights] [image path] -dont_show
TIEU LUAN MOI download : skknchat123@gmail.com moi nhat
Google Colab suppresses OpenCV's graphic functions, preventing direct image display Instead, results must be saved to a file, such as predictions.jpg To bypass OpenCV's graphic errors, use the argument -dont_show.
Như vậy chúng ta đã hoàn thành quá trình huấn luyện và dự báo một mô hình object detection trên google colab.
Mô hình YOLO yêu cầu thời gian huấn luyện lâu do cần dự đoán nhãn và tọa độ cho 10,647 bounding boxes từ một ảnh đầu vào kích thước 418x418 Cụ thể, YOLO xử lý 13x13, 26x26 và 52x52 lưới, mỗi lưới có 3 bounding boxes Với kích thước batch là 64 ảnh và tổng số max_batches là 5000, quá trình huấn luyện trở nên phức tạp hơn.
Chúng ta cần dự báo tổng cộng 3.4 triệu bounding boxes, tính từ 10647x5000x64 Đây là một con số lớn, do đó quá trình huấn luyện trên Google Colab sẽ mất vài giờ.
Google Colab chỉ cho phép huấn luyện trong 12 giờ liên tục, vì vậy việc ước lượng thời gian huấn luyện là cần thiết để không vượt quá giới hạn này Trong bài viết này, tôi sẽ chia sẻ một số mẹo để ước tính và tiết kiệm thời gian huấn luyện hiệu quả.
Để ước tính tổng thời gian huấn luyện, bạn nên dựa trên thời gian huấn luyện của một batch Ví dụ, nếu một batch mất 3.6 giây, thì 5000 batches sẽ tiêu tốn khoảng (3.6 x 5000)/3600 = 5 giờ Tuy nhiên, đây chỉ là ước tính tương đối vì không phải tất cả các batch đều có thời gian huấn luyện giống nhau Trong trường hợp gặp phải những batch có hình ảnh lỗi hoặc định dạng không tương thích, thời gian huấn luyện có thể kéo dài đáng kể do cần phải gỡ lỗi.
Hãy save log trong quá trình huấn luyện và vẽ biểu đồ loss function.
Biểu đồ hàm mất mát giúp xác định liệu quá trình huấn luyện đã đạt trạng thái hội tụ hay chưa Nếu nhận thấy hàm mất mát có dấu hiệu hội tụ, bạn có thể xem xét dừng sớm quá trình huấn luyện.
Huấn luyện mô hình trên nhiều GPU song song giúp tăng tốc độ đào tạo, nhưng chỉ áp dụng cho những ai sở hữu nhiều GPU, không sử dụng được trên Google Colab Để tối ưu hóa hiệu suất, cần giảm learning rate theo cấp số nhân; ví dụ, khi sử dụng 4 GPU, learning rate mới nên được thiết lập bằng 1/4 learning rate mặc định trên 1 GPU Việc điều chỉnh này sẽ giúp quá trình huấn luyện diễn ra nhanh chóng và hiệu quả hơn.
Sử dụng mô hình pretrain trên bộ dữ liệu tương đồng giúp các trọng số của mô hình pretrain và mô hình tối ưu gần gũi nhau Điều này cho phép giảm thiểu số bước huấn luyện cần thiết để đạt được kết quả tốt, so với việc sử dụng mô hình pretrain được huấn luyện trên bộ dữ liệu khác biệt.
TIEU LUAN MOI download : skknchat123@gmail.com moi nhat
Update cuDNN version (đối với các bạn huấn luyện trên máy tính cá nhân, môi trường xịn sò của google colab đã update sẵn cuDNN)
Cấu hình cuDNN đã được cải thiện đáng kể với các kiến trúc mới, giúp tăng tốc quá trình huấn luyện Việc sử dụng cuDNN phiên bản 7.6 có thể tăng tốc gấp đôi so với phiên bản 6.0, vì vậy hãy đảm bảo cập nhật cuDNN nếu bạn đang sử dụng phiên bản cũ Tuy nhiên, cần lưu ý rằng cuDNN phải tương thích với phiên bản CUDA để tránh các lỗi phát sinh.
Khi lựa chọn kiến trúc cho mô hình YOLO, hãy cân nhắc sử dụng kiến trúc đơn giản, vì sự đa dạng của các kiến trúc này phụ thuộc vào base network Đối với những tác vụ có ít lớp, độ chính xác giữa mô hình phức tạp và đơn giản không chênh lệch nhiều Bạn nên đặt ra tiêu chuẩn về mAP cho mô hình và thử nghiệm với các kiến trúc đơn giản như tiny YOLO, vì chúng có thể đạt tiêu chuẩn đó Thêm vào đó, tốc độ dự báo nhanh và khả năng triển khai trên các thiết bị IoT cấu hình thấp là những lợi thế nổi bật của các mô hình này.
KẾT QUẢ
TIEU LUAN MOI download : skknchat123@gmail.com moi nhat
TIEU LUAN MOI download : skknchat123@gmail.com moi nhat
TIEU LUAN MOI download : skknchat123@gmail.com moi nhat
TIEU LUAN MOI download : skknchat123@gmail.com moi nhat
2 Bài 25 - YOLO You Only Look Once - Khanh blog
TIEU LUAN MOI download : skknchat123@gmail.com moi nhat